线程
与进程近似,线程是允许应用程序并发执行多个任务的一种机制。如下图所示,一个进程可以包含多个线程。同一个程序的所有线程均会独立地执行相同的程序,且会共享统一份全局内存区域,包括初始化数据段(initialized data)、未初始化数据段(uninitialized data)以及堆内存段(heap segment)。
注意:
传统意义上的UNIX进程是多线程程序的一个特例,该进程值包括一个线程。
下图作了简化。特别是,线程栈(thread stack)的位置可能会与共享库、共享内存区域混在一起,这取决于创建线程、加载共享库,以及映射共享内存的具体顺序。而且,对于不同的Linux发行版,线程地址也会有所不同。
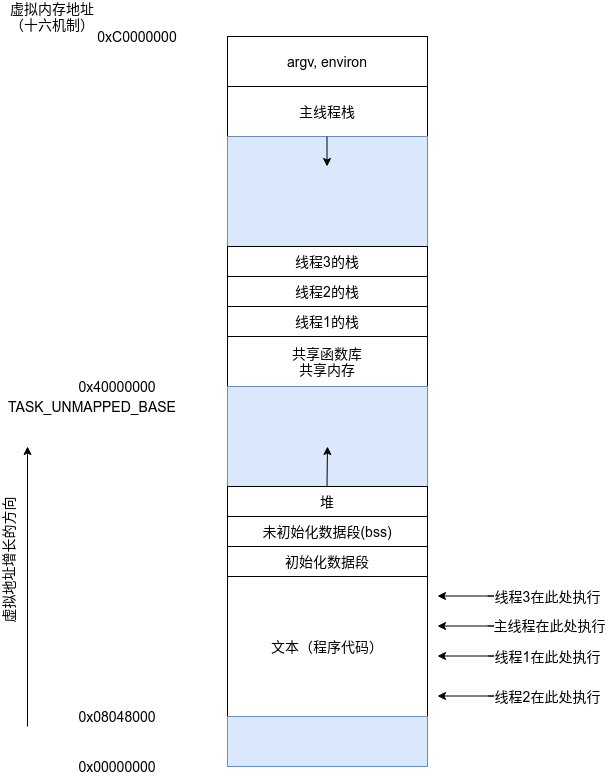
进程的问题
-
进程间信息难以共享。只能通过进程间通信(IPC)的方式在进程间进行信息交换。
-
调用
fork()来创建进行的代价较高。即使利用写时复制(copy-on-write)技术,仍然需要复制内存页表(page table)和文件描述符(file descriptor table)等多种进程属性。
线程解决了上述的痛点:
-
线程之间可以快速共享信息。
-
创建线程效率比创建进程快10倍以上。(创建线程是
clone()实现的)。
线程之间共享的数据
全局性:
-
全局内存
-
进程ID、父进程ID
-
进程组ID、会话ID
-
控制终端
-
打开的文件描述符
-
进程凭证
-
fcntl()创建的记录锁(record clock) -
信号(signal)处置
-
文件系统相关信息
-
间隔定时器、POSIX定时器
-
系统V信号量撤销值
-
资源限制
-
CPU时间消耗
-
资源消耗
-
nice值
独有属性:
-
线程ID
-
信号掩码
-
线程特有数据
-
备选信号栈
-
errno变量
-
浮点型环境
-
实时调度策略(real-time scheduleing policy)和优先级
-
CPU亲和力(affinity)
-
能力(capablity)
-
栈、本地变量和函数的调用链接信息
线程ID
进程内部每一个线程都有一个唯一标识,成为线程ID。线程ID会返回pthread_create()的调用者,一个线程可以通过pthread_self()来获取线程ID。
POSIX线程ID和Linux专有的系统调用
gettid()返回的线程ID
并不相同。POSIX线程ID由线程库实现来负责分配和维护。gettid()返回的线程ID是由内核(Kernel)分配的数字,类似于进程ID(process ID)。虽然在LINUX NPTL线程实现中,每个POSIX线程都对应于唯一的线程内核线程ID,但应用程序一般无需了解内核ID。
线程特有数据
线程特有数据使函数得以为每个调用线程分别维护一份变量的副本。线程特有数据是长期存在的。在同一线程对相同通过的函数历次调用期间,每个线程的变量会持续存在,函数可以向每个调用线程返回各自的结果缓存区。
实时调度策略和优先级
在Linux中,调度进程使用的CPU默认模型是循环时间共享。在这种模型中,每个进程轮流使用CPU一段时间,这段时间称之为时间片或者量子。循环时间共享满足了交互式多任务的两个重度需求:
-
公平性:每个进程都有机会用到CPU。
-
响应度:一个进程在使用CPU之前无需等待太常的时间。
进程的nice值允许进程间接地影响内核的调度算法,每个进程都有一个nice值,其中取值范围是-20(高优先级)~19(低优先级),默认值是0。
CPU亲和力(affinity)
LINUX提供非标准系统调用来修改进程的硬CPU亲和力:sched_setaffinity()和sched_getaffinity()。
CPU亲和力是线程级特性,可以调整线程组中的每一个线程。
1 |
|
Pthreads
线程数据类型(Pthreads data type)
| 数据类型 | 描述 |
|---|---|
pthread_t |
线程ID |
pthread_mutex_t |
互斥对象(Mutex) |
pthread_mutexattr_t |
互斥属性对象 |
pthread_cond_t |
条件变量(condition ariable) |
pthread_condattr_t |
条件变量的属性对象 |
pthread_key_t |
线程特有数据的键 |
pthead_once_t |
一次性初始化控制上下文(control context) |
pthead_attr_t |
线程的属性对象 |