堆与栈
进程内存布局
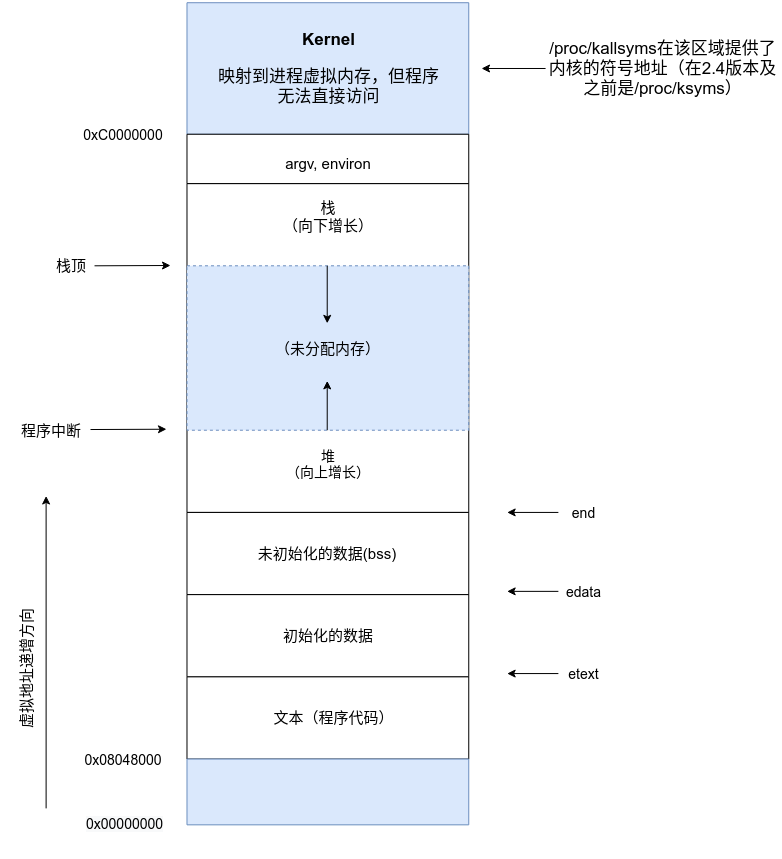
如下图所示,对于每个程序所分配的内存由很多部分组成,通常称之为“段”(segment)。
-
文本段(text)包括进程运行的程序机器语言指令。文本段具有只读属性,以防止进程通过错误指针意外修改自身指令。
-
初始化数据段(BSS)包括为未进行显式初始化的全局变量和静态变量。
对于初始化和未初始化数据段即用户初始化数据段(user-initialized data segment)和零初始化数据段(zero-initialized data segment)。
-
栈(stack)是一个动态增长和收缩的段,由栈帧(stack frames)组成。系统会为每个当前调用的函数分配一个栈帧。栈帧中存储了函数的局部变量(所谓自动变量)、实参和返回值。
-
堆(heap)是可在运行时(变量)动态进行内存分配的一块区域。堆顶端成为program break。
栈
栈是程序运行的基础。当每一个函数被调用时,操作系统会在栈顶分配一块连续的内存。这块内存被称为帧(frame)。
这里讨论的栈是用户栈(user stack),和内核栈区分开来。内核栈是每个进程保留在内核内存中的内存区域,在执行系统调用的过程中供(内核)内部函数调用使用。
栈是自顶向下增长的,一个程序的调用栈最底部,除去入口帧(entry frame),就是main()函数对应的帧。随着mian()函数一层一层调用,栈会一层一层地扩展;调用结束后,栈会一层一层地回溯,把内存释放回去。

每个栈帧包括如下信息:
-
函数实参和局部变量:这些变量都是在函数调用时自动创建的,被称为C语言中的自动变量。函数返回时将自动销毁这些变量(因为栈帧会被释放),这也是自动变量与静态变量(以及全局)变量主要的语义区别:后者与函数执行无关,且长期存在。
-
(函数)调用的链接信息:每个函数都会用到一些CPU寄存器,比如程序计数器,其值向下一条要执行的机器语言指令。当每个函数调用另外一个函数时,会在被调用函数的栈帧中保存这些寄存器的副本,以便函数返回时能够为函数调用者将寄存器恢复原状。
在调用的过程中,一个新的帧会分配足够的空间存储寄存器的上下文。在函数里使用到的通用寄存器会在栈保存一个副本,当这个函数调用结束,通过副本,可以恢复出原本的寄存器的上下文,就像什么都没有经历一样。此外,函数所需要使用到的局部变量,也都会在帧分配的时候被预留出来。
那么,一个函数运行时,是怎么确定需要多大的帧?
这要归功于编译器。在编译、优化代码时,一个函数就是一个最小的编译单元。
在这个函数里,编译器得指导有哪些寄存器、栈上要放哪些局部变量,而这些都要在编译时确定。所以编译器就需要为每个局部变量明确大小,以便于预留空间。
在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上。
存放在栈上的问题
栈上的内存分配是非常高效的。只需要改动栈指针(stack pointer),就可以预留相应的空间;把栈指针改动回来,预留的空间又会被释放掉。预留和释放只是动动寄存器,不涉及额外计算、不涉及系统调用,因而效率很高。
所以理论上说,只要可能,我们应该把变量分配到栈上,这样可以达到更好的运行速度。
那为什么在实际工作中,我们又要避免把大量的数据分配在栈上呢?
这主要是考虑到调用栈的大小,避免栈溢出(stack overflow)。一旦当前程序的调用栈超出了系统允许的最大栈空间,无法创建新的帧,来运行下一个要执行的函数,就会发生栈溢出,这时程序会被系统终止,产生崩溃信息。过大的栈内存分配是导致栈溢出的原因之一,更广为人知的原因是递归函数没有妥善终止。一个递归函数会不断调用自己,每次调用都会形成一个新的帧,如果递归函数无法终止,最终就会导致栈溢出。
堆
当我们需要动态大小的内存时,只能使用堆,比如可变长度的数组、列表、哈希表、字典,它们都分配在堆上。进程可以通过增加堆的大小来分配内存,所谓堆就是一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾,随着内存的分配和释放而增减。通常将堆的当前内存边界成为program break。
除了动态大小的内存需要被分配到堆上外,动态生命周期的内存也需要分配到堆上。
上文中我们讲到,栈上的内存在函数调用结束之后,所使用的帧被回收,相关变量对应的内存也都被回收待用。所以栈上内存的生命周期是不受开发者控制的,并且局限在当前调用栈。
而堆上分配出来的每一块内存需要显式地释放,这就使堆上内存有更加灵活的生命周期,可以在不同的调用栈之间共享数据。
存放在堆上的问题
堆内存的这种灵活性也给内存管理带来很多挑战。
如果手工管理堆内存的话,堆上内存分配后忘记释放,就会造成内存泄漏。一旦有内存泄漏,程序运行得越久,就越吃内存,最终会因为占满内存而被操作系统终止运行。
如果堆上内存被多个线程的调用栈引用,该内存的改动要特别小心,需要加锁以独占访问,来避免潜在的问题。比如说,一个线程在遍历列表,而另一个线程在释放列表中的某一项,就可能访问野指针,导致堆越界(heap out of bounds)。而堆越界是第一大内存安全问题。
如果堆上内存被释放,但栈上指向堆上内存的相应指针没有被清空,就有可能发生**使用已释放内存(use after free)**的情况,程序轻则崩溃,重则隐含安全隐患。根据微软安全反应中心(MSRC)的研究,这是第二大内存安全问题。
GC、ARC
为了避免堆内存手动管理造成问题,Java等语言选择追踪式垃圾回收管理堆内存。Swift等语言选择自动引用计数。
-
追踪式垃圾回收
这种方式通过定期标记(mark)找出不再被引用的对象,然后将其清理(sweep)掉,来自动管理内存,减轻开发者的负担。
-
自动引用计数
在编译时,它为每个函数插入 retain/release 语句来自动维护堆上对象的引用计数,当引用计数为零的时候,release 语句就释放对象。
比较:
-
从效率上来说,GC 在内存分配和释放上无需额外操作,而 ARC 添加了大量的额外代码处理引用计数,所以 GC 效率更高,吞吐量(throughput)更大。
-
但是,GC 释放内存的时机是不确定的,释放时引发的 STW(Stop The World),也会导致代码执行的延迟(latency)不确定。所以一般携带 GC 的编程语言,不适于做嵌入式系统或者实时系统。当然,Erlang VM是个例外, 它把 GC 的粒度下放到每个 process,最大程度解决了 STW 的问题。
小结
对于存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。堆可以存入大小未知或者动态伸缩的数据类型。
堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。但也导致堆变量的管理非常复杂,手工管理会引发很多内存安全性问题,而自动管理,无论是 GC 还是 ARC,都有性能损耗和其它问题。
栈上存放的数据是静态的,静态大小,静态生命周期;堆上存放的数据是动态的,动态大小,动态生命周期。
来源
-
Unix系统编程手册